Edit, pour illustrer le signal
![]()
Mais ceci est loin du son réel, il faudrait y ajouter le reste du spectre. C'est un son "pur". Il faut bien voir l'amplitude d'une part, et la fréquence d'autre part. Si au cours du temps vous rapprochez, resserrez les petites vagues
Le son sera plus aigue, et si elles sont plus amples, il sera plus fort. Ça pourra peut être être utile.
Concernant la description d'un son par fourier:
http://www.web-sciences.com/do(...)2.php
En résumé, c'est un moyen mathématique de sommer des fonctions simples (Sinus et cosinus) pour reproduire n'importe quel signal. C'est démontré par les matheux qu'on est capable de décomposer toute fonction continue de cette façon, surprenant non. Et donc les gentils physiciens somment plein de fonctions de ce type pour aboutir à quelque chose de similaire à la courbe "réelle". Bref, pour éviter de dire des conneries, j'arrête.
Concernant le sujet, plus directement:
"A chaque échantillon (correspondant à un intervalle de temps) est associée une valeur qui détermine la valeur de la pression de l'air à ce moment, le son n'est donc plus représenté comme une courbe continue présentant des variations mais comme une suite de valeurs pour chaque intervalle de temps."
Donc en gros, à chaque instant (plutôt intervalle, voire plus bas), t'as une courbe qui te décrit ton signale sonore, donne sa fréquence (donc hauteur du son) et son amplitude (intensité, volume)
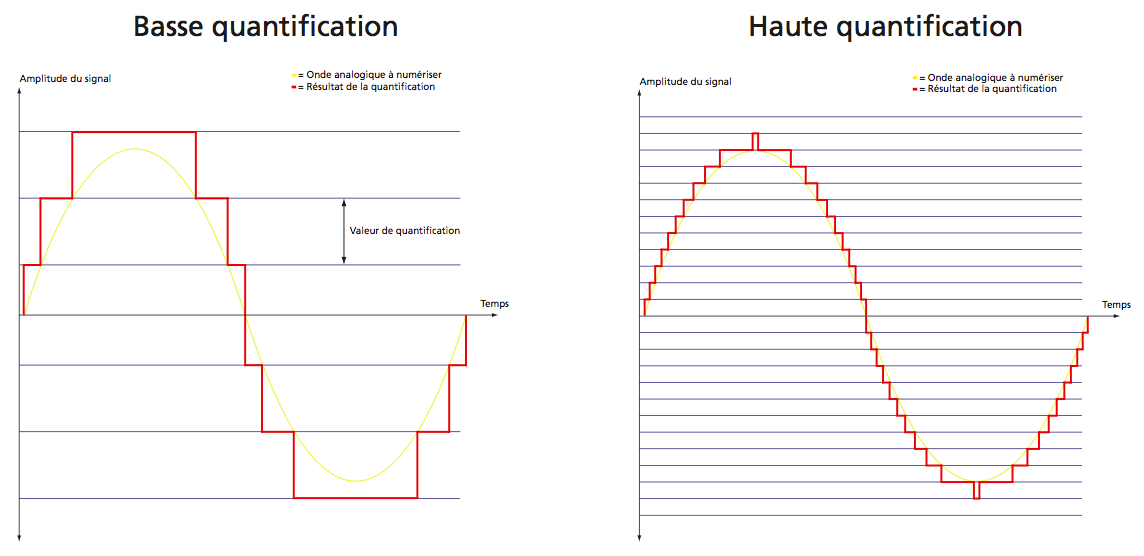
"L'ordinateur travaille avec des bits, il faut donc déterminer le nombre de valeurs que l'échantillon peut prendre, cela revient à fixer le nombre de bits sur lequel on code les valeurs des échantillons.
Avec un codage sur 8 bits, on a 28 possibilités de valeurs, c'est-à-dire 256 valeurs possibles
Avec un codage sur 16 bits, on a 216 possibilités de valeurs, c'est-à-dire 65536 valeurs possibles
Avec la seconde représentation, on aura bien évidemment une qualité de son bien meilleure, mais aussi un besoin en mémoire beaucoup plus important.
Enfin, la stéréophonie nécessite deux canaux sur lesquels on enregistre individuellement un son qui sera fourni au haut-parleur de gauche, ainsi qu'un son qui sera diffusé sur celui de droite.
Un son est donc représenté (informatiquement) par plusieurs paramètres :
la fréquence d'échantillonnage
le nombre de bits d'un échantillon
le nombre de voies (une seule correspond à du mono, deux à de la stéréo, et quatre à de la quadriphonie)"
L'échantillonnage lui, correspond à l'intervalle définie. Donc en gros, un échantillonnage minable serait comme regarder un film en 5 images/secondes, mais en son. D'où l'intérêt d'avoir un échantillonnage élevé. (Au final, on se place à 44kHz, un peu comme les 24img/sec d'un film, parce que l'homme fait plus trop la différence après).
le reste ici
http://www.commentcamarche.net(...)rique